선형회귀알고리즘의 목표 : 입력 데이터(x) 와 타깃 데이터(y)를 통해 기울기(a)와 절편(b)를 찾는 것
= 산점도 그래프를 잘 표현하는 직선의 방정식을 찾는 것
- 푸는 방법 : 경사 하강법 (gradient descent) , 정규방정식(normal equation), 결정트리, 등
경사하강법
- 모델이 데이터를 잘 표현할 수 있도록 기울기(변화율)를 사용하여 모델을 조금씩 조정하는 최적화 알고리즘
예측값과 변화율
- 딥러닝에서는, 기울기 a를 가중치를 의미하는 w나 계수를 의미하는 θ 로 표기
- y(타깃데이터)는 y ̂(y-hat)으로 표기
- y=ax+b 를 y ̂=wx+b로
- 가중치 w와 절편 b는 알고리즘이 찾은 규칙, y ̂는 예측값(우리가 예측한 값)
훈련데이터에 잘 맞는 w와 b찾기
from sklearn.datasets import load_diabetes
diabetes = load_diabetes() #diabetes에 당뇨병 데이터 저장
x=diabetes.data[:,2]
y=diabetes.target
1. w와 b 무작위로 초기화 하기
예시)
w=1.0
b=1.0
2. 훈련데이터의 첫번째 샘플 데이터로 y ̂얻기
- 훈련데이터의 첫번째 샘플 x[0]에 대한 y ̂계산 -> y_hat변수에 저장
y_hat = x[0] * w + b
print(y_hat) #1.0616962065186886
3. 타깃과 예측 데이터 비교하기
y[0]과 y_hat값 비교
print(y[0]) #151.0
4. w값 조절해 예측값 바꾸기
y_hat 과 타깃(y[0])의 차이가 큼 -> w와 b 무작위 설정
-> w와 b 조금씩 변경
w_inc = w+0.1 #1차 함수의 기울기를 0.1만큼 높여준다고 생각
y_hat_inc = x[0] * w_inc + b
print(y_hat_inc) #1.0678658271705574- y_hat보다 조금 증가
5. w값 조정한 후 예측값 증가 정도 확인하기
- w가 0.1만큼 증가했을 때 y_hat이 얼마나 증가했는지 계산 (y_hat증가량 / w증가량)
w_rate = (y_hat_inc - y_hat)/(w_inc -w)
print(w_rate) #0.061696206518688734- w_rate 는 첫번째 훈련 데이터 x[0]에 대한 w의 변화율
- 변화율은 양수 이므로 w값을 증가시키면 y_hat값 증가
- 변화율이 음수라면? w값을 감소시키면 y_hat값 감소
- w_rate에 대한 코드를 수식으로 적어 정리하면 변화율 = 훈련 데이터의 첫번째 샘플인 x[0]

w_rate = (y_hat_inc - y_hat) / (w_inc - w) = ((x[0] × w_inc + b) - (x[0] × w + b)) / (w_inc - w)
= (x[0] × ((w + 0.1) - w)) / ((w + 0.1) - w) = x[0]
변화율로 가중치(w) 업데이트하기
(1) 변화율이 양수일 때
- w가 증가 y_hat증가
(2) 변화율이 음수일 때
- w가 감소 y_hat증가
- w에 w_rate(변화율) 더하는 방법!
w_new = w + w_rate
변화율로 절편(b) 업데이트하기
- 절편 b에 대한 변화율을 구한 다음 변화율로 b 업데이트
- b 0.1만큼 증가시킨후 y_hat이 얼만큼 증가했는지 계산
b_inc = b + 0.1
y_hat_inc = x[0] * w + b_inc
print(y_hat_inc) #1.1616962065186887- 변화율 계산
b_rate = (y_hat_inc - y_hat) / (b_inc - b)
print(b_rate) #1.0- 변화율의 값은 1 : b가 1만큼 증가하면 y_hat도 1만큼 증가

b_rate=(y_hat_inc-y_hat)/(b_inc-b) = ((x[0]×w+b_inc)-(x[0]×w+b))/(b_inc-b)
= ((b+0.1)-b)/((b+0.1)-b)=1
- 즉 b를 업데이트하기 위해서는 변화율이 1이므로 1을 더하면 됨
b_new = b + 1
print(b_new) #2.0
위의 방법들은 수동적인 방법!
이유 1) y_hat이 y에 한참 미치지 못하는 값의 경우, w와 b를 더 큰 폭으로 수정 X, 앞에서 변화율만큼 수정 했지만 특별한 기준 잡기 어려움
이유 2) y_hat이 y보다 커지면 y_hat을 감소시키지 X
오차역전파(backpropagation)사용 - 가중치와 절편 보다 적절하게 업데이트
오차역전파 : y ̂과 y 차이를 이용하여 w와 b 업데이트
1. 오차와 변화율을 곱하여 가중치 업데이트하기
x[0]일때 w의 변화율과 b의 변화율에 오차를 곱한다음
업데이트 된 w_new와 b_new 출력
err=y[0]-y_hat
w_new=w+w_rate*err
b_new=b+1*err
print(w_new,b_new)
# 10.250624555904514 150.9383037934813
2. 두번째 샘플 x[2]를 사용하여 오차를 구하고 새로운 w와 b 구하기
w_rate식을 정리하면 샘플값과 같아지므로 w_rate별도로 계산 X, 샘플값그대로 사용
y_hat = x[1]*w_new+b_new
err=y[1]-y_hat
w_rate=x[1]
# w_rate식을 정리하면 샘플값과 같아지므로 w_rate별도로 계산 X, 샘플값그대로 사용
w_new=w_new+w_rate*err
b_new=b_new+1*err
print(w_new,b_new)
# 14.132317616381767 75.52764127612664
3. 전체 샘플 반복하기
for x_i,y_i in zip(x,y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w=w+w_rate *err
b=b+1*err
print(w,b)
# 587.8654539985689 99.40935564531424cf) python의 zip()함수 : 여러개의 배열에서 동시에 요소를 하나씩 꺼내줌
위의 코드 : 입력 x와 타깃y 배열에서 요소를 하나씩 꺼내여 err계산 후 w와 b 업데이트
4. 그래프 그려 위에서 얻어낸 모델이 전체 데이터를 잘 표현하는지 확인
plt.scatter(x,y)
pt1=(-0.1,-0.1*w+b)
pt2=(0.15,0.15*w+b)
plt.plot([pt1[0],pt2[0]],[pt1[1],pt2[1]])
plt.xlabel('x')
plt.ylabel('y')
plt.show()
그래프그리기 전에 아래 코드 까먹지 말고 입력하기
입력하지 않으면 NameError: name 'plt' is not defined 과 같은 에러가 뜸
import numpy as np
import matplotlib.pyplot as plt
5. 여러 에포크(epoch)를 반복하기
for i in range(1,100):
for x_i,y_i in zip(x,y):
y_hat = x_i * w + b
err = y_i - y_hat
w_rate = x_i
w=w+w_rate *err
b=b+1*err
print(w,b)
#913.5973364345905 123.39414383177204다시 그래프로 나타내면
plt.scatter(x,y)
pt1=(-0.1,-0.1*w+b)
pt2=(0.15,0.15*w+b)
plt.plot([pt1[0],pt2[0]],[pt1[1],pt2[1]])
plt.xlabel('x')
plt.ylabel('y')
plt.show()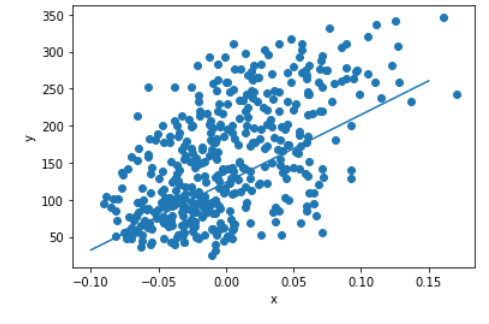
위의 경우 머신러닝 모델: y ̂=913.6x + 123.4
6. 모델로 예측하기
입력 x에 없었던 새로운 데이터가 발생했다고 가정
-> 이 데이터에 대한 예측값을 얻으려면?
-> 우리가 찾은 모델에 x를 넣고 계산
ex. x=0.18일때
x_new = 0.18
y_pred = x_new * w +b
print(y_pred)
# 287.8416643899983이 데이터를 산점도 위에 나타내면
plt.scatter(x,y)
plt.scatter(x_new,y_pred)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
'Computer Science > 인공지능(AI)' 카테고리의 다른 글
| TinyML이란? (0) | 2021.04.20 |
|---|---|
| mnist모델 구축하기 - KERAS (0) | 2021.03.21 |
| [Deep Learning] 선형회귀(Linear Regression) (0) | 2020.05.25 |
| [Deep Learning] 딥러닝을 위한 도구들 - 넘파이(Numpy), 맷플롯립(Matplotlib) (0) | 2020.05.21 |
| [Deep Learning] 구글 코랩(google colab) (0) | 2020.05.19 |